![]()
Index
- Introduction
- Types of paradigms
- Sync Vs. Async training
- Types of distributed strategy
- Conclusion
1. Introduction
Training a machine learning model is a very time-consuming task. As datasets size increases, it becomes very hard to train models within a limited time frame. To solve this type of problem, distributed training approaches are used. Using distributed training, we can train very large models and speed up training time. Tensorflow provides a high-end API to train your models in a distributed way with minimal code changes.
2. Types of Paradigms
Two types of paradigms used for distributed training.
- Data parallelism: In data parallelism, models are replicated into different devices (GPU) and trained on batches of data.
- Model parallelism: When models are too large to fit on a single device then it can be distributed over many devices.
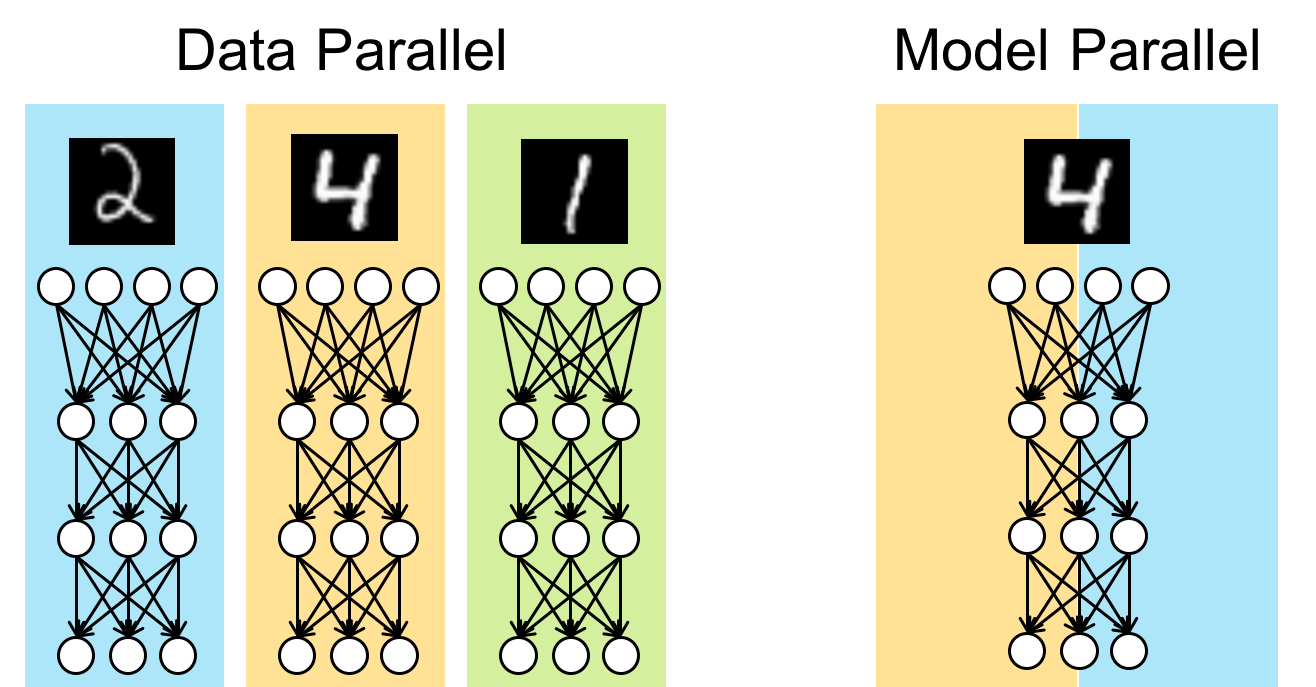 |
|---|
| Fig.1 - Data Parallelism vs. Model Parallelism |
3. Synch vs. Asynch training
There are two common ways of distributing training with data parallelism.
Synch training (supported via all-reduce architecture): All devices (GPUs) train over different slices of input data in sync and aggregating gradient at each step.there are three common strategies comes under sync training Async Training (supported via parameter server architecture): all workers are independently training over the input data and updating variables asynchronously.
4. Types of distributed strategy
- Mirrored Strategy
- Worked on one machine/ worker and multiple GPUs
- The model (neural network architecture) is replicated across all GPUs
- Each model is trained on different slices of data and weight updating is done using efficient cross-device communication algorithms (all-reduce algorithms) such as Hierarchical copy, reduction to one device, NCCL (default).
 |
|---|
| Fig.2 - Operations of Mirrored Strategy with two GPU devices. |
As you see in the figure is that a neural network having two layers (layer A, layer B) are replicated on each GPUs. Each GPU is trained on a slice of data, during the backpropagation cross-device communication algorithm is used to update the weights.
- TPU Strategy
- TPU strategy is the same as mirrored strategy, the only difference is that it runs on TPUs instead of GPUs
- Distributed training architecture is also the same as a mirrored strategy.
- Multiworker Mirrored Strategy
- The model is trained across multiple machines having multiple GPUs
- Workers are run in lock-step and synchronizing the gradient at each step
- Either ring all-reduce or hierarchical all-reduce communication used for cross-device communication.
 |
|---|
| Fig.3 - Multiworker Mirrored Strategy |
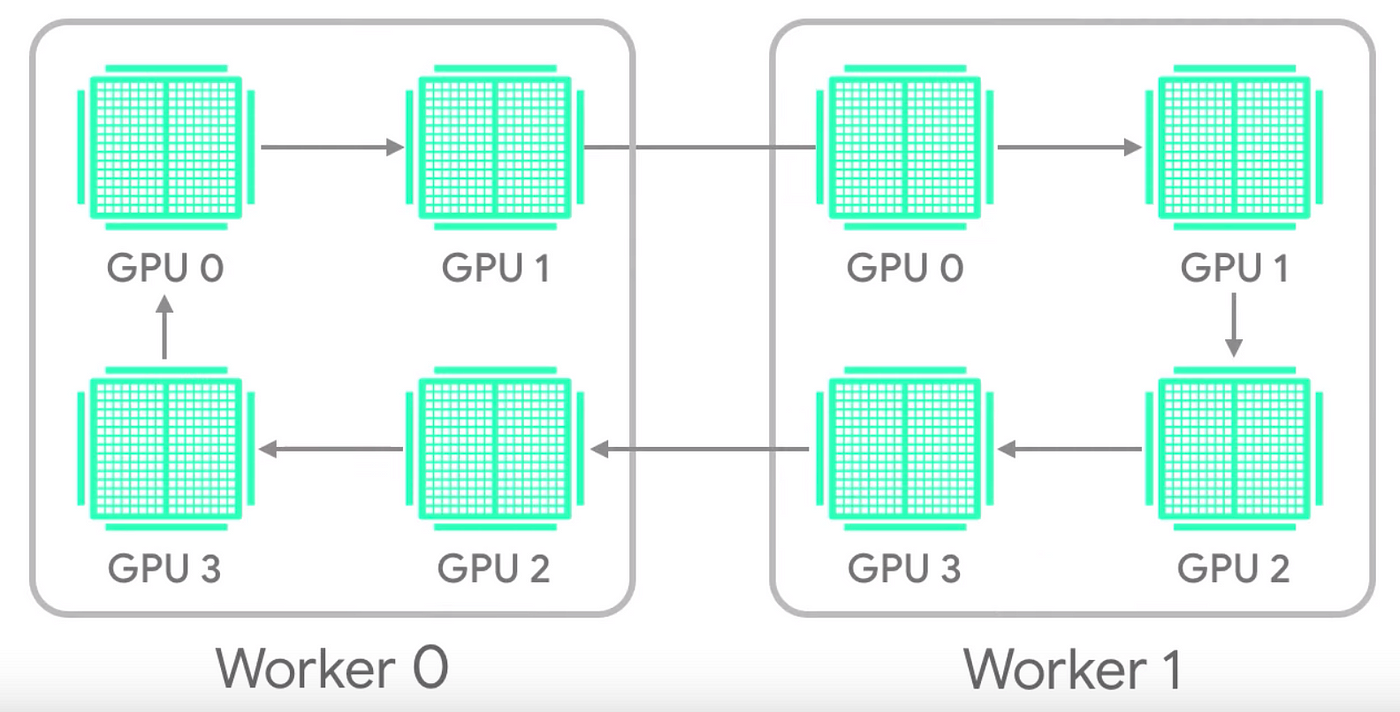 |
|---|
| Fig.4 - Ring all-reduce |
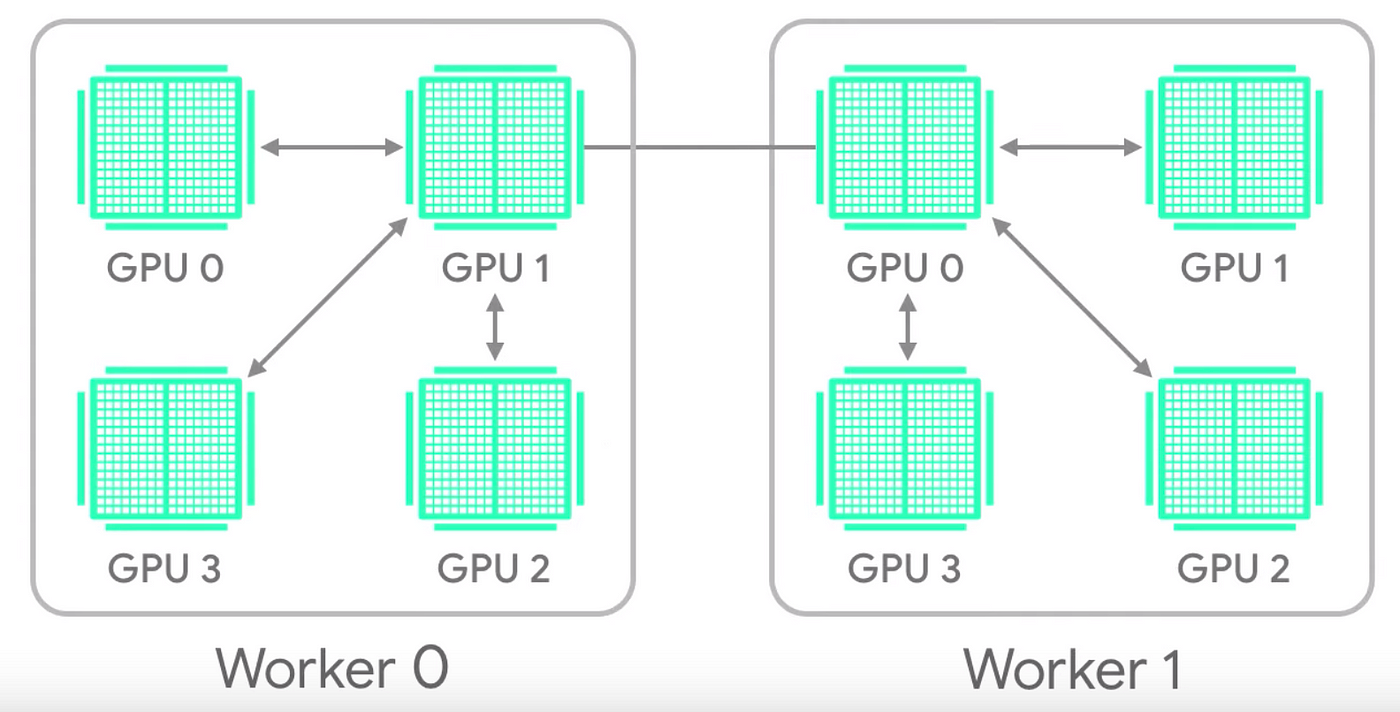 |
|---|
| Fig.5 - Hierarchical all-reduce |
- Central Storage Strategy
- Performed on one machine with multiple GPUs
- Variables are not mirrored instead, they are placed on the CPU and operations are replicated all local GPUs.
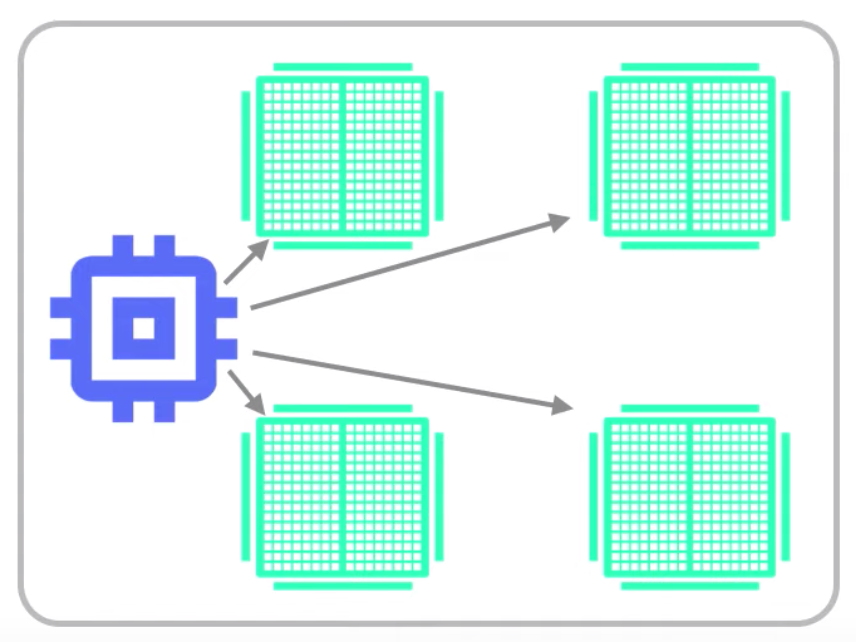 |
|---|
| Fig.6 - Central Storage Strategy |
- One Device Strategy
- Run-on a single device GPU or CPU
- Typical for testing
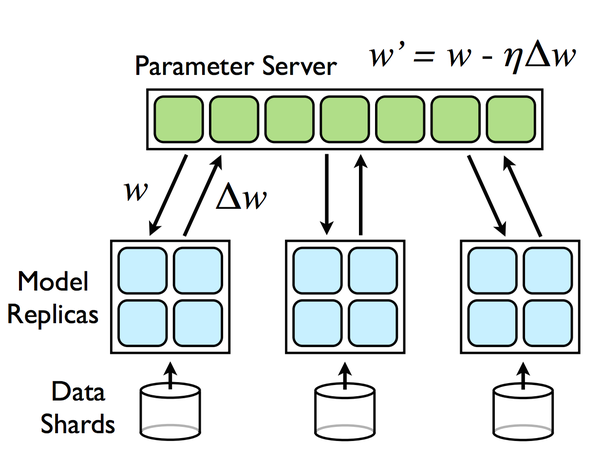
- Parameter Server Strategy
- Implemented on multiple machines
- In this setup, some machines are designated as workers and some as parameter servers
- Each variable of the model is placed on one parameter server
- Computation is replicated across all GPUs of all the workers.
- Worker tasks are read input, variables, compute forward and backward and send updates to the parameters servers.
 |
|---|
| Fig.7 - Parameter Server Strategy |
5. Conclusion
You shouldn’t always distribute. Smaller models can train faster on one machine. When you have a lot of data and your data size and your model continue to grow, in that case, you can go with distributed training approaches.
6. References
Thanks for reading !